Wow! but how?
Як працює технологія BioCoherence
Вау! Але як? Це основне питання, яке ставлять нові користувачі після першого сканування.
Дозвольте пояснити простими словами. Якщо вам цікаві більш детальні пояснення, є більш глибоке пояснення після цього.
Швидке пояснення
Від сирих записів до інсайтів
BioCoherence починається з запису ЕКГ (електрокардіограма), використовуючи медично сертифікований сенсор. Хоча основна мета запису — це електрична активність серця, сенсор також фіксує електричну активність всього тіла, від лівого пальця до правого. Ці дані відображаються у вигляді основного запису ЕКГ, домінованого ритмом серця, але також показують інші тонкі електричні активності.
Обробка та аналіз даних
Сирі дані до ознак: Перший запис ЕКГ включає як основний ритм серця, так і інші електричні частоти. Автоматичне фільтрування виключає проблемні удари (наприклад, через рух), що дозволяє провести точний аналіз.
Багаторівневий аналіз:
- Аналіз першого порядку:
- Витягує первинні дані з ЕКГ, такі як специфічні частоти (VLF, LF, HF) і часові інтервали (HRV).
- Використовує обширні опубліковані дослідження для отримання академічних біомаркерів.
- Аналіз другого порядку:
- Аналізує дані першого порядку, щоб виявити нові властивості, такі як гармоніки та ентропія.
- Обчислює додаткову інформацію про біомаркери, включаючи якості, такі як увага та намір.
- Аналіз третього порядку:
- Визначає зв'язки та резонанси між елементами, показуючи енергетичні взаємозв'язки (наприклад, між органами).
- Використовує складні алгоритми для обчислення рецептів ТКМ та пов'язаних елементів.
- Аналіз четвертого порядку:
- Обчислює ресурси та пріоритети, вказуючи, які біомаркери є найзначнішими.
- Інтегрує результати в узагальнений огляд здоров'я користувача.
Переваги для користувачів:
- Модуль сканування: Надає детальний аналіз біомаркерів, карти тіла та графіки.
- Модуль тестування: Пропонує зворотний зв'язок у реальному часі та відкриту систему створення.
- Модуль балансу: Генерує користувацькі медитації та звіти.
Щоденна цінність: Зосереджується на інформації вищого порядку (ресурси, пріоритети), що надає найбільш практичні інсайти для користувачів, одночасно дозволяючи доступ до всіх детальних даних.
На завершення, BioCoherence використовує передові математичні алгоритми для перетворення сирих даних ЕКГ у цінні інсайти про здоров'я, пропонуючи багаторівневий аналіз, який розкриває всебічну інформацію про електричну активність тіла. Цей інноваційний підхід надає користувачам дієві дані для покращення їх благополуччя.
Глибоке пояснення
Давайте заглибимося... Я спробую відповісти якомога глибше, не входячи в технічні деталі...
На початку була сира запис
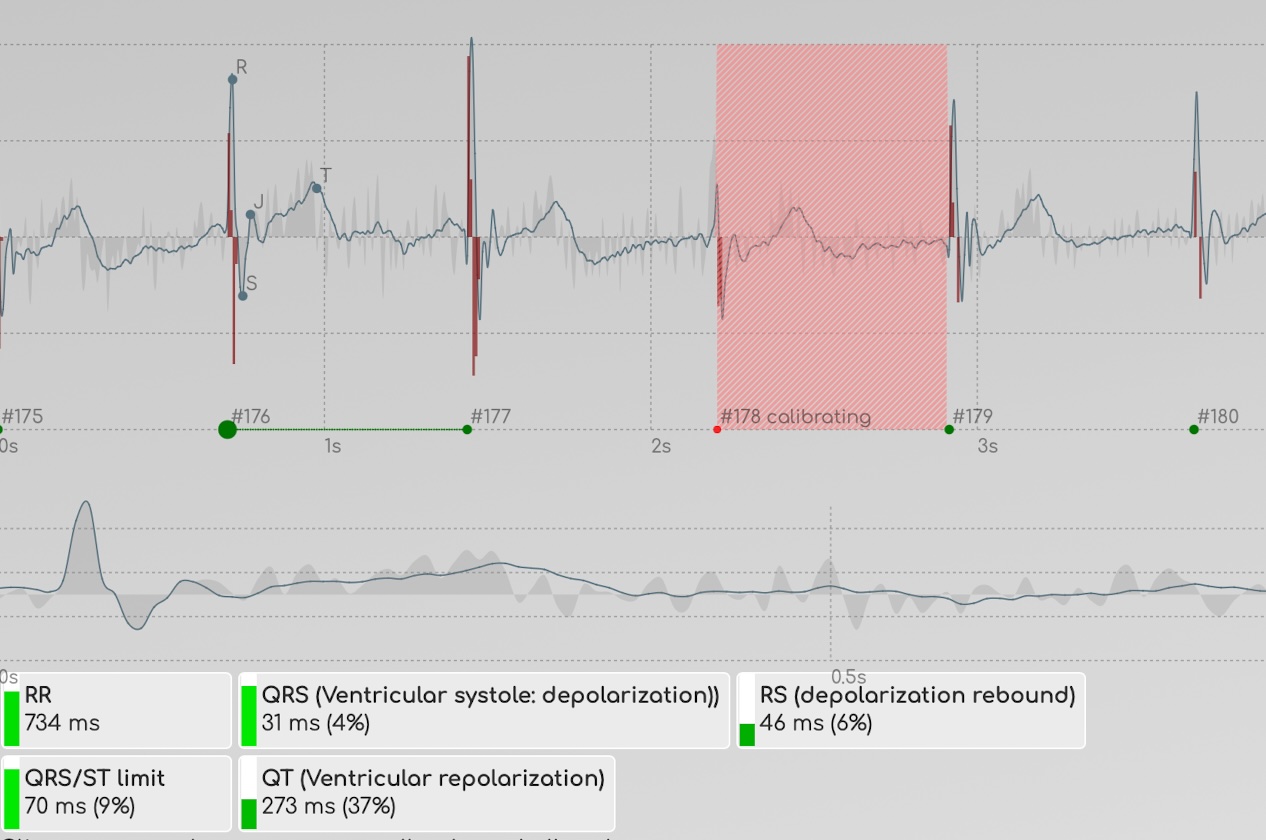 BioCoherence починається з запису ЕКГ. ЕКГ означає «електрокардіограма», що означає, що ми використовуємо медично сертифікований пристрій (наш датчик), який в основному призначений для запису електричної активності серця. Але є одна деталь: серце є найпотужнішим, але не єдиним органом в організмі, який має електричну активність. Ми знаємо, що мозок також має (це показується на ЕЕГ, електроенцефалограмі), але насправді кожен орган, кожен атом, кожна система має магнітну та електричну активність. Коли ми вимірюємо від лівого пальця до правого, датчик записує набагато більше, ніж просто імпульс частоти серцебиття: він записує всю магнітну та електричну активність тіла.
BioCoherence починається з запису ЕКГ. ЕКГ означає «електрокардіограма», що означає, що ми використовуємо медично сертифікований пристрій (наш датчик), який в основному призначений для запису електричної активності серця. Але є одна деталь: серце є найпотужнішим, але не єдиним органом в організмі, який має електричну активність. Ми знаємо, що мозок також має (це показується на ЕЕГ, електроенцефалограмі), але насправді кожен орган, кожен атом, кожна система має магнітну та електричну активність. Коли ми вимірюємо від лівого пальця до правого, датчик записує набагато більше, ніж просто імпульс частоти серцебиття: він записує всю магнітну та електричну активність тіла.
Отже, перше, що ми маємо, це багато електричної інформації, яка відображається як основний запис ЕКГ. Це явно домінує ритмом основного серцебиття, але під цим основним процесом відбувається багато інших процесів, і це відображається в BioCoherence як сіра лінія, що вібрує навколо основної хвилі. Саме тут ми знайдемо дані для відтворення тисяч активностей біомаркерів.
Ви можете побачити це на сторінках частот: внизу графіка частот завжди є темна лінія, яка є найважливішою частотою (частота биття), але ви також можете бачити багато інших частот, присутніх у записі. Цей графік частот є іншим способом побачити запис хвилі, перетворюючи інформацію на основі часу в графік на основі частоти; але це все ще та ж сама сира інформація.
Ми додали автоматичне фільтрування, щоб виключити проблемні удари (оскільки, наприклад, користувач рухався, і електричний сигнал вийшов за межі нормального на кілька секунд), і в цей момент ми можемо почати аналізувати цей запис для виділення характеристик.
Виникаючі властивості
У теорії систем існує важливе поняття, яке називається «виникаючі властивості». Якщо коротко, воно стверджує, що з кожним новим рівнем складності з'являються нові властивості, які не є безпосередньо похідними від властивостей нижчого рівня. Наприклад, ви можете змішати 2 високозаймисті гази (кисень та водень) і отримати стабільну рідину (воду), властивості якої неможливо передбачити з цих газів. Саме тому ми проводимо аналіз на багаторівневому порядку, кожен рівень використовує властивості попереднього рівня, і кожен рівень виявляє нові зв'язки, які не могли існувати на попередньому рівні.
Все це здійснюється виключно за допомогою математики. На відміну від більшості інших «пристроїв енергетичної оцінки», які в основному базуються на генераторах випадкових чисел, алгоритми в BioCoherence повністю засновані на математиці, тому результати завжди будуть точно такими ж для одного запису. Насправді весь розрахунок виконується знову щоразу, коли ви відкриваєте запис.
Тоді відбувається аналіз першого порядку
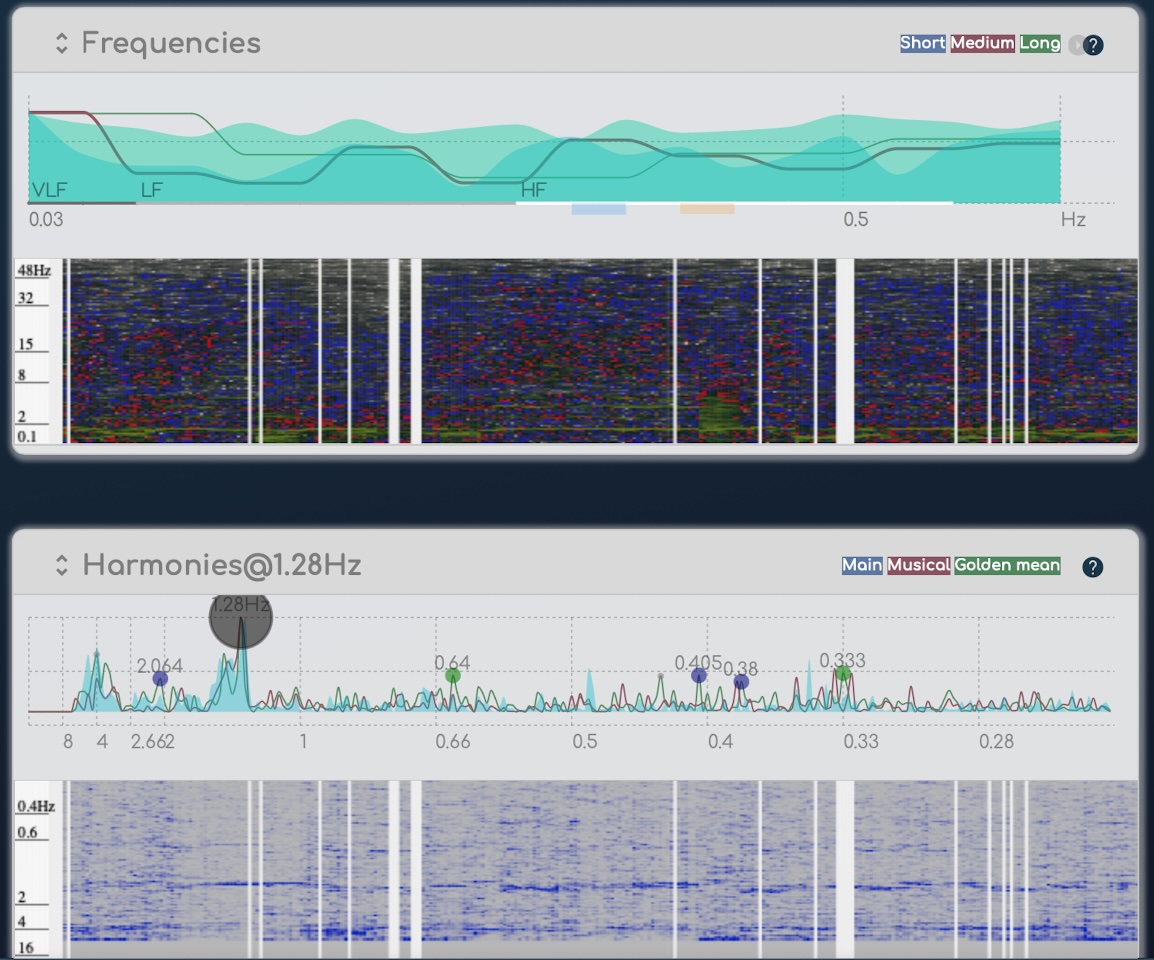 Тепер наші алгоритми проведуть аналіз першого порядку на цих сирих даних, щоб витягти інформацію першого порядку. Це може походити, наприклад, з конкретних діапазонів частот (як для VLF, LF або HF) або з аналізу за часовими інтервалами (як для HRV).
Тепер наші алгоритми проведуть аналіз першого порядку на цих сирих даних, щоб витягти інформацію першого порядку. Це може походити, наприклад, з конкретних діапазонів частот (як для VLF, LF або HF) або з аналізу за часовими інтервалами (як для HRV).
Ми використали багато опублікованих досліджень від дуже різноманітних дослідників ЕКГ, які зазвичай не спілкуються між собою, щоб створити широкі списки інформації, яку ми вилучили на цьому рівні.
Цей аналіз першого порядку дає нам в основному академічні біомаркери, оскільки зазвичай на цьому етапі зупиняються офіційні дослідження. Це тому, що обробка сигналів зазвичай досить обмежена в медичних дослідженнях*, тоді як я застосував обробку музичних сигналів, яка є значно більш просунутою. Оскільки DSP (цифрові сигнальні процесори) замінили аналогову обробку в музиці з 90-х років, було проведено величезну кількість досліджень для розуміння, емуляції та обробки цифрових записів за допомогою багатьох інструментів, таких як звукові ефекти або різні інструменти для налаштування цифрового музичного контенту в реальному часі. Це, по суті, ті ж алгоритми, які ми використовуємо в BioCoherence: просунуті математичні методи, які знають звукові інженери в обробці музики, але ніхто не використовує в медичних додатках.
*: до речі, всі жартують, що в 1994 році була опублікована рецензована стаття, в якій пояснювався дуже новаторський метод обчислення площі під кривою (помпезно названій AUC) електрокардіограми. Це було визнано достатньо цікавим, щоб бути опублікованим у рецензованому журналі. Але, як знає будь-хто з невеликим математичним навчанням, це називається «інтеграл», викладається в коледжі і було відкрито багато століть тому. Тим не менш, більшість офіційних досліджень перебуває на цьому рівні математики.Цікаві речі починаються в аналізі другого порядку
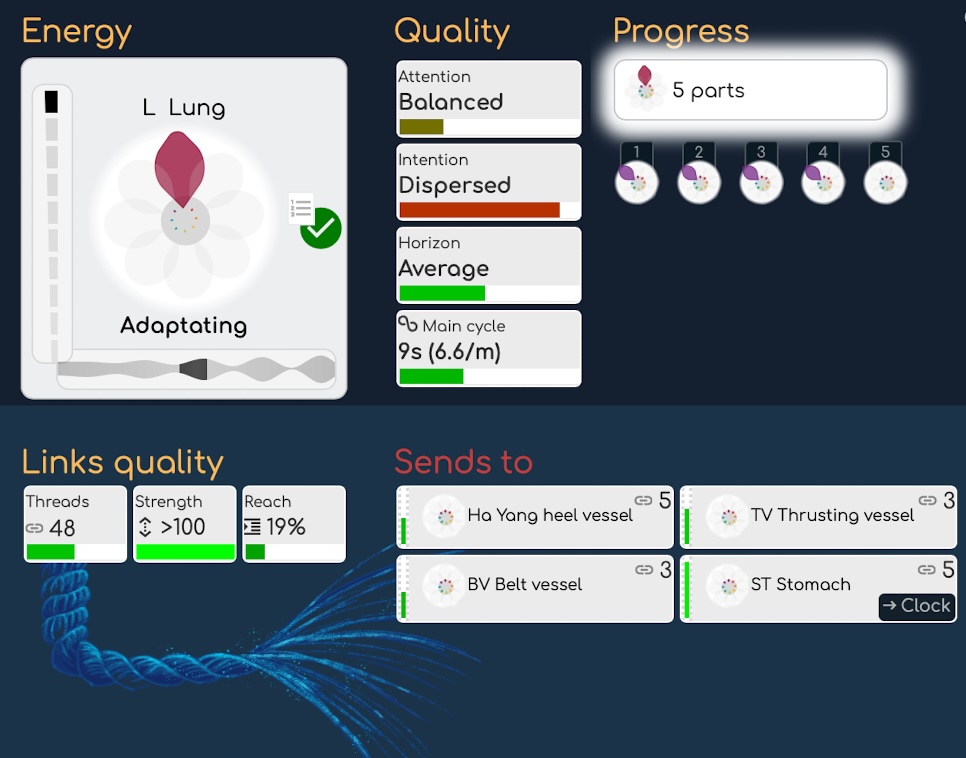 Коли ми отримуємо ці дані першого порядку, ми отримуємо нові властивості і можемо провести кілька аналізів другого порядку на цих нових властивостях. Наприклад, в аналізі першого порядку ми розрахували спектр: завдяки математичному алгоритму, званому FFT (Швидке перетворення Фур'є), ми можемо відобразити сирий запис у вигляді частот замість хвилі. Тепер, в аналізі другого порядку, ми розрахуємо кепстр (який є FFT другого порядку), який дозволяє нам виділити не частоти, а гармоніки в сигналі: одним словом, він виділяє частоти, які резонують гармонійно разом. Використовуючи ці результати, ми отримаємо нові біомаркери.
Коли ми отримуємо ці дані першого порядку, ми отримуємо нові властивості і можемо провести кілька аналізів другого порядку на цих нових властивостях. Наприклад, в аналізі першого порядку ми розрахували спектр: завдяки математичному алгоритму, званому FFT (Швидке перетворення Фур'є), ми можемо відобразити сирий запис у вигляді частот замість хвилі. Тепер, в аналізі другого порядку, ми розрахуємо кепстр (який є FFT другого порядку), який дозволяє нам виділити не частоти, а гармоніки в сигналі: одним словом, він виділяє частоти, які резонують гармонійно разом. Використовуючи ці результати, ми отримаємо нові біомаркери.
- Приклад ще одного аналізу другого порядку - це розрахунок ентропії (або «агітації») кожного біомаркера. Іншими словами, він показує, наскільки конкретний біомаркер є статичним або збудженим.
- Ще один приклад аналізу другого порядку - це якості, які ми показуємо справа від біомаркера, такі як увага, намір і горизонт (властивості, витягнуті з їхніх музичних якостей) та основні цикли.
Існує багато аналізів другого порядку, проведених на сигналі, і тому ми отримуємо багато нових інформацій про біомаркери. Але на цьому ми не зупинимося, адже цей новий рівень розкриває деякі нові цікаві властивості, які раніше не існували.
Знову ж, ми використовували багато опублікованих досліджень від дуже різноманітних дослідників, тепер не на даних ЕКГ, а на даних, специфічних для терапії, таких як Аюрведа, ТКМ, енергетична оцінка або сучасна медична наука.
Аналіз третього порядку: зв'язки та резонанси
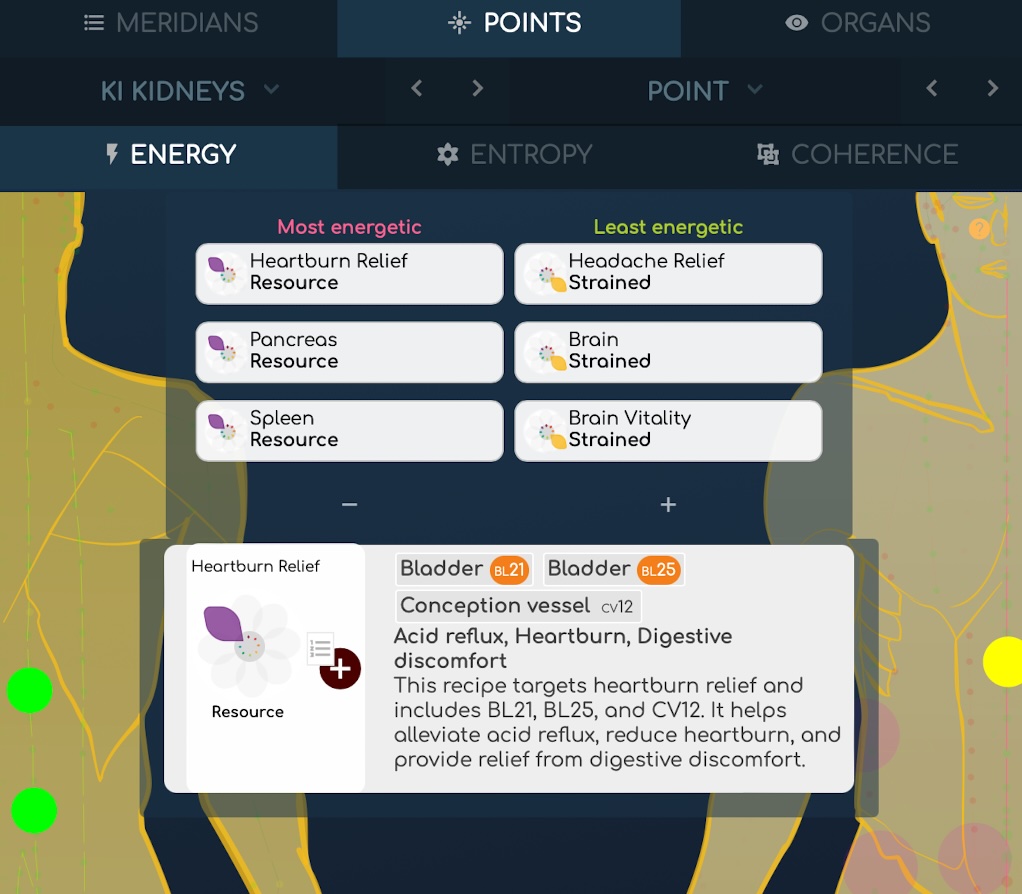 Тепер з'являється ще один рівень складності з його новими дива. Використовуючи всі нові дані другого порядку, які у нас є, ми можемо розрахувати нові властивості, наприклад, зв'язки між елементами. Ці зв'язки відображаються скрізь в додатку, як на графіках, так і на картах тіла; вони дозволяють нам зрозуміти основні енергетичні відносини між, скажімо, органами: якщо орган пов'язаний з іншим, це може вказувати на те, що відбувається енергетичний перенесення, і один допомагає або допомагає іншому.
Тепер з'являється ще один рівень складності з його новими дива. Використовуючи всі нові дані другого порядку, які у нас є, ми можемо розрахувати нові властивості, наприклад, зв'язки між елементами. Ці зв'язки відображаються скрізь в додатку, як на графіках, так і на картах тіла; вони дозволяють нам зрозуміти основні енергетичні відносини між, скажімо, органами: якщо орган пов'язаний з іншим, це може вказувати на те, що відбувається енергетичний перенесення, і один допомагає або допомагає іншому.
Ці зв'язки обчислюються за допомогою досить складного багатовимірного алгоритму, який використовує просунуту векторну математику для виявлення спільних резонансів між елементами. Але ми намагалися приховати цю складність і представити лише результат, яким є чіткі зв'язки між елементами.
- В рамках процесу ми обчислили тонни даних, і це відображається як «якості зв'язків» та пов'язані елементи для кожного біомаркера.
- Ще один приклад третього порядку - це обчислення рецептів ТКМ. Ми зворотним чином розробили логіку рецептів ТКМ, які використовують кілька акупунктурних точок для лікування конкретних симптомів. Зворотно кажучи, ми говоримо: якщо ці точки пов'язані цими властивостями третього порядку, це може вказувати на асоційований симптом їх групи.
Знову ж таки, ми використовували опубліковані дослідження з терапевтично специфічних даних. Окрім рецептів ТКМ, логіка зв'язків походить з роботи багатьох практиків, з якими ми працювали, які намагаються піднятися по причинному ланцюгу, щоб знайти корінні причини.
Чому б не йти далі?
 Добре, поки ми цим займаємось, давайте продовжимо з цими новими емерджентними властивостями і зробимо 4-й рівень аналізу. З усіма цими новими даними ми тепер можемо розрахувати ресурси та пріоритети. Ресурси розраховуються за допомогою алгоритму 4-го рівня, який використовує інформацію з усіх нижчих рівнів для обчислення єдиного «значення ресурсу», як показано на сторінці ресурсів (коли ви натискаєте на ресурс, щоб змінити його за потреби). Це вказує на те, як біомаркер у даній родині є «на вершині ланцюга щедрості». Теорія ресурсів походить з роботи Крістін Дегой і детальніше пояснюється у її майбутніх книгах.
Добре, поки ми цим займаємось, давайте продовжимо з цими новими емерджентними властивостями і зробимо 4-й рівень аналізу. З усіма цими новими даними ми тепер можемо розрахувати ресурси та пріоритети. Ресурси розраховуються за допомогою алгоритму 4-го рівня, який використовує інформацію з усіх нижчих рівнів для обчислення єдиного «значення ресурсу», як показано на сторінці ресурсів (коли ви натискаєте на ресурс, щоб змінити його за потреби). Це вказує на те, як біомаркер у даній родині є «на вершині ланцюга щедрості». Теорія ресурсів походить з роботи Крістін Дегой і детальніше пояснюється у її майбутніх книгах.
Пріоритети, з іншого боку, є певною мірою «недооціненими», «на дні харчового ланцюга». Вони видобуваються з інформації 3-го порядку та нижче, відповідно до енергії, збудження або когерентності в даній родині біомаркерів. Оскільки ми обчислили енергію, збудження та когерентність, ми тепер можемо визначити пріоритетами елементи з занадто низькою енергією, занадто високою енергією, занадто статичні та занадто збуджені елементи, а також когерентні системи, які можуть вказувати на те, що щось відбувається.
А тепер давайте танцювати в зворотному напрямку
Повернімося до нашого прикладу з водою H2O. Коли ви вперше бачите воду, ви не аналізуєте її з точки зору газоподібних компонентів. Ви тільки бачите властивості верхнього порядку: що ви можете її пити; що ви можете в ній плавати; що вона може змішуватися з іншими елементами тощо. Зазвичай, коли ми бачимо складну систему, ми спостерігаємо за нею ззовні і бачимо лише властивості верхнього порядку. І щоразу, коли ми відкривали додатковий рівень порядку, ми усвідомлювали, як це корисно для повсякденних користувачів. Тож у BioCoherence ми зазвичай зворотнімо важливість інформації і починаємо з ресурсів (інформація 4-го порядку), пріоритетів (інформація 3-го порядку), квітки біомаркерів (інформація 2nd порядку) та якостей біомаркерів (інформація 3-го порядку). Все ще можливо перейти до інформації першого рівня (хвиля та спектр), але найбільшу щоденну цінність несуть верхні рівні.
 Порядки складності показані через верхні праві стрілки на головному екрані (їх можна натиснути, щоб повторити обчислення на кожному рівні), але логіка меню (і порядок звіту) зворотна: вона починається з верхніх рівнів (баланс: ресурси, пріоритети та звіт), оскільки це зазвичай найважливіша інформація, з якої слід починати.
Порядки складності показані через верхні праві стрілки на головному екрані (їх можна натиснути, щоб повторити обчислення на кожному рівні), але логіка меню (і порядок звіту) зворотна: вона починається з верхніх рівнів (баланс: ресурси, пріоритети та звіт), оскільки це зазвичай найважливіша інформація, з якої слід починати.
І це все щодо частини сканування.