Wow! but how?
BioCoherenceテクノロジーの仕組み
わお!でもどうやって? これは新しいユーザーが初めてスキャンした後に尋ねる主な質問です。
簡単に説明しましょう。もっと深く知りたい方は、後に詳しい説明があります。
簡単な説明
生データからインサイトへ
BioCoherenceは、医療認証されたセンサーを使用してECG(心電図)記録から始まります。主に心臓の電気活動を記録する一方で、センサーは体全体の電気活動も捉え、左手の指から右手の指までをカバーします。この包括的なデータは、心臓のリズムが支配する主要なECG記録として表示されますが、他の微細な電気活動も示します。
データ処理と分析
生データから特徴へ: 初期のECG記録には、心臓の主要なリズムと他の電気周波数が含まれています。自動フィルタリングにより、問題のあるビート(例えば、動きによる)を除外し、正確な分析を可能にします。
多層分析:
- 一次分析:
- ECGから主なデータを抽出し、特定の周波数(VLF、LF、HF)や時間ベースの間隔(HRV)を示します。
- 広範な公表された研究を使用して、学術的バイオマーカーを導出します。
- 二次分析:
- 一次データを分析して、新たな特性(調和やエントロピーなど)を明らかにします。
- 注意や意図などの特性を含む追加のバイオマーカー情報を計算します。
- 三次分析:
- 要素間のリンクや共鳴を特定し、エネルギー的な関係を示します(例:臓器間)。
- 複雑なアルゴリズムを使用して、TCMレシピや関連要素を計算します。
- 四次分析:
- リソースと優先順位を計算し、最も重要なバイオマーカーを示します。
- ユーザーの健康に関する一貫した概要に発見を統合します。
ユーザーベネフィット:
- スキャンモジュール: 詳細なバイオマーカー分析、体のマップとグラフを提供します。
- テストモジュール: リアルタイムのバイオフィードバックとオープンな作成システムを提供します。
- バランスモジュール: カスタムメディテーションとレポートを生成します。
日常の価値: リソースや優先順位などの高次の情報に焦点を当て、ユーザーに最も実用的なインサイトを提供しつつ、すべての詳細データへのアクセスも可能にします。
結論として、BioCoherenceは高度な数学的アルゴリズムを使用して、生のECGデータを価値ある健康インサイトに変換し、体の電気活動に関する包括的な情報を明らかにする多層分析を提供します。この革新的なアプローチは、ユーザーのウェルビーイングを向上させるための実行可能なデータを提供します。
詳細な説明
詳しく掘り下げてみましょう... 技術的な内容に入らず、できるだけ深く答えようとします...
最初は生の記録でした
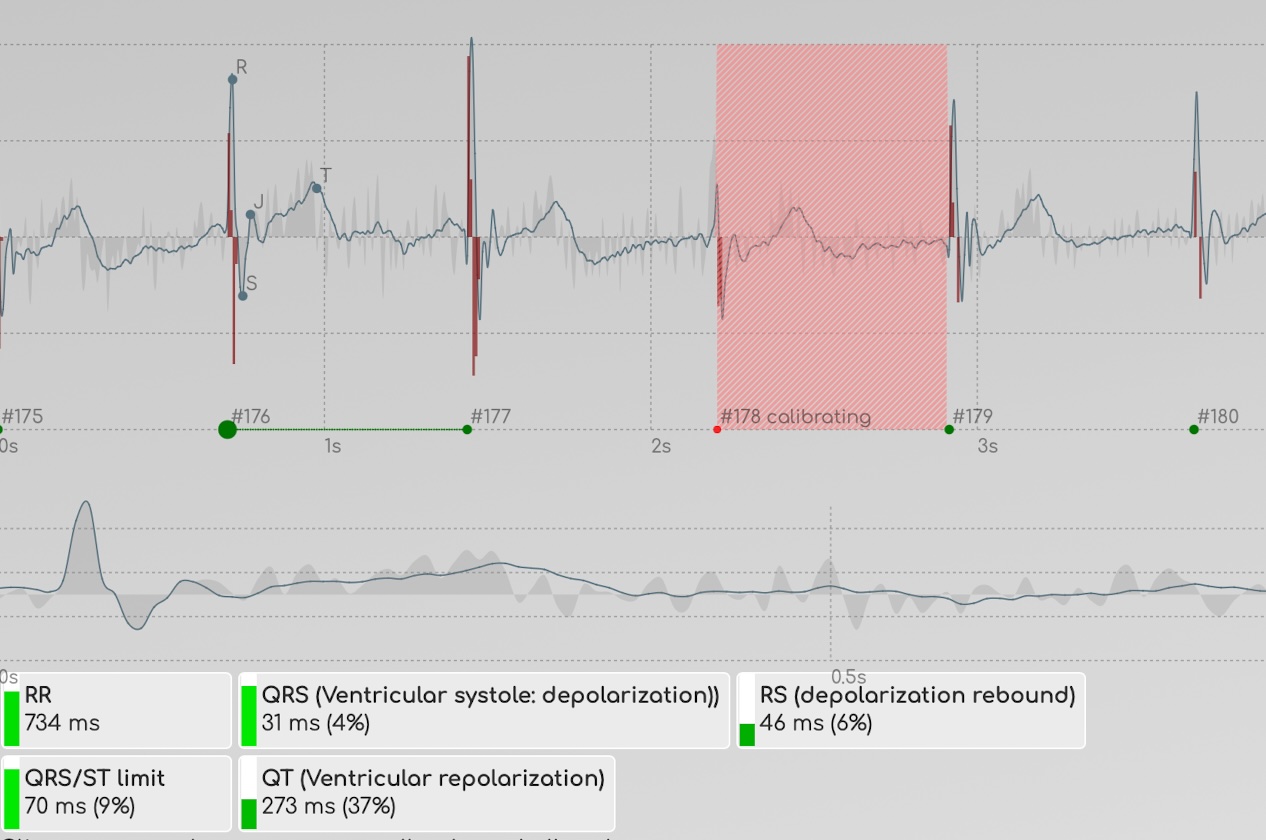 BioCoherenceはECG記録から始まります。ECGは「心電図」を意味し、心臓の電気的活動を記録するために主に使用される医療認証されたデバイス(当社のセンサー)を使用します。しかし、ここに落とし穴があります:心臓は最も強力ですが、電気的活動を持つ体の唯一の臓器ではありません。脳もそうです(EEG、脳波計に表示されます)が、実際にはすべての臓器、すべての原子、すべてのシステムには磁気的および電気的活動があります。左手の指から右手の指まで測定することで、センサーは心臓の拍動率インパルスだけでなく、全身の磁気的および電気的活動を記録します。
BioCoherenceはECG記録から始まります。ECGは「心電図」を意味し、心臓の電気的活動を記録するために主に使用される医療認証されたデバイス(当社のセンサー)を使用します。しかし、ここに落とし穴があります:心臓は最も強力ですが、電気的活動を持つ体の唯一の臓器ではありません。脳もそうです(EEG、脳波計に表示されます)が、実際にはすべての臓器、すべての原子、すべてのシステムには磁気的および電気的活動があります。左手の指から右手の指まで測定することで、センサーは心臓の拍動率インパルスだけでなく、全身の磁気的および電気的活動を記録します。
したがって、最初に得られるのは多くの電気情報であり、これは主なECG記録として表示されます。これは明らかに心拍の主要なリズムに支配されていますが、この主要な活動の下で多くのことが進行しており、BioCoherenceでは主波の周りで振動する灰色のラインとして表示されます。ここで、何千ものバイオマーカーの活動を再構築するためのデータを見つけることができます。
周波数ページで見ることができます:周波数グラフの下部近くには常に暗い線があり、これは最も重要な周波数(拍動率)ですが、記録内に存在する他の多くの周波数も見ることができます。この周波数グラフは、時間ベースの情報を周波数ベースのグラフに変換することによって、記録波を別の方法で見ることができるが、これは依然として同じ生の情報です。
ユーザーが動いたために電気信号が数秒間オフチャートになった場合など、問題のあるビートを除外するために自動フィルタリングを追加しました。この時点で、私たちはこの記録を分析し、特徴を抽出し始めることができます。
出現する特性
システム理論には「出現する特性」という重要な概念があります。簡単に言えば、各新しい複雑さのレベルには、下位のレベルの特性から直接導かれない新しい特性が現れることを示しています。たとえば、2つの非常に可燃性のあるガス(酸素と水素)を混ぜると、これらのガスからは予測不可能な特性を持つ安定した液体(水)が得られます。これが、私たちが多層階注文分析を行う理由であり、各レベルは前のレベルの特性を使用し、各レベルが前のレベルには存在し得なかった新しい関係を明らかにします。
これらはすべて純粋に数学によって行われます。主にランダム数生成器に基づいている他の「エネルギー評価装置」とは異なり、BioCoherenceのアルゴリズムは純粋に数学に基づいているため、録音の結果は常に正確に同じになります。実際、録音を開くたびに計算全体が再度行われます。
次に、一次分析が行われます
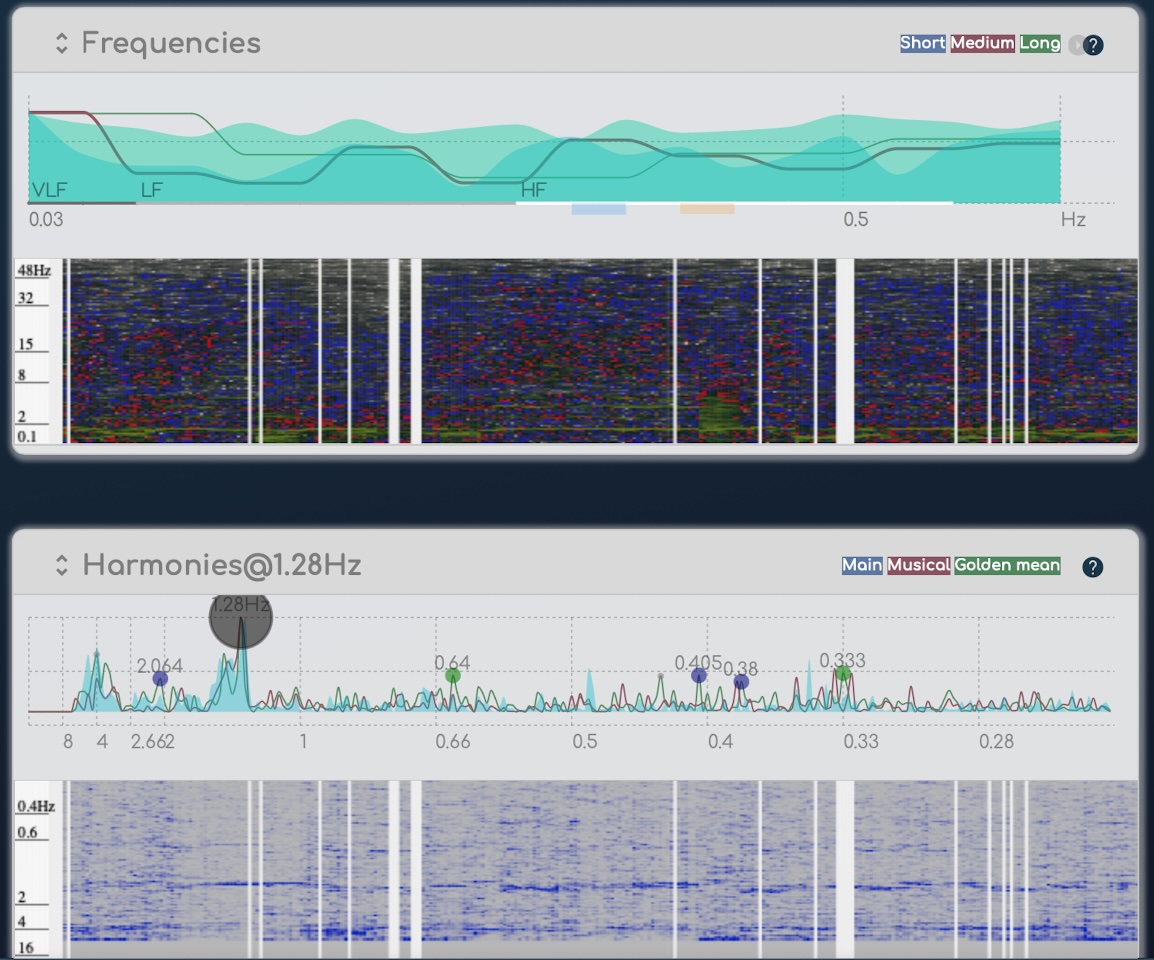 さて、私たちのアルゴリズムはこの生データに対して一次分析を行い、一次情報を抽出します。これは、特定の周波数または周波数範囲(VLF、LF、またはHFのように)や時間ベースの間隔分析(HRVのように)から得られることがあります。
さて、私たちのアルゴリズムはこの生データに対して一次分析を行い、一次情報を抽出します。これは、特定の周波数または周波数範囲(VLF、LF、またはHFのように)や時間ベースの間隔分析(HRVのように)から得られることがあります。
私たちは、通常は一緒に話さない非常に多様なECG研究者によって発表された多くの研究を利用して、このレベルで抽出した幅広い情報のリストを作成しました。
この一次分析は、主に学術的バイオマーカーを提供します。これは、公式な研究が通常ここで止まるためです。信号処理は医療研究では通常かなり限られているからです*。一方、私は音楽信号処理を適用しており、これははるかに進んでいます。90年代以降、DSP(デジタル信号処理器)が音楽におけるアナログ処理に取って代わったため、デジタル録音を理解し、エミュレートし、処理するために多くの研究が行われてきました。音響効果やリアルタイムでデジタル音楽コンテンツを調整するためのさまざまなツールのような多くのツールが含まれます。これは基本的に、BioCoherenceで使用している同じアルゴリズムです:音楽処理において音響エンジニアが知っている高度な数学であり、医療アプリケーションでは誰も使用していません。
*: 余談として、1994年に発表された査読付き論文が、心電図の曲線下の面積(威張ってAUCと呼ばれる)を計算する非常に新しい方法を説明していると冗談を言う人が多いです。これは査読付きジャーナルに掲載されるのに十分に興味深いと見なされました。しかし、少しでも数学の訓練を受けた人なら誰でも知っているように、これは「積分」と呼ばれ、大学で学び、何世紀も前に発見されています。それにもかかわらず、ほとんどの公式研究はこのレベルの数学にとどまっています。二次分析が面白くなり始める
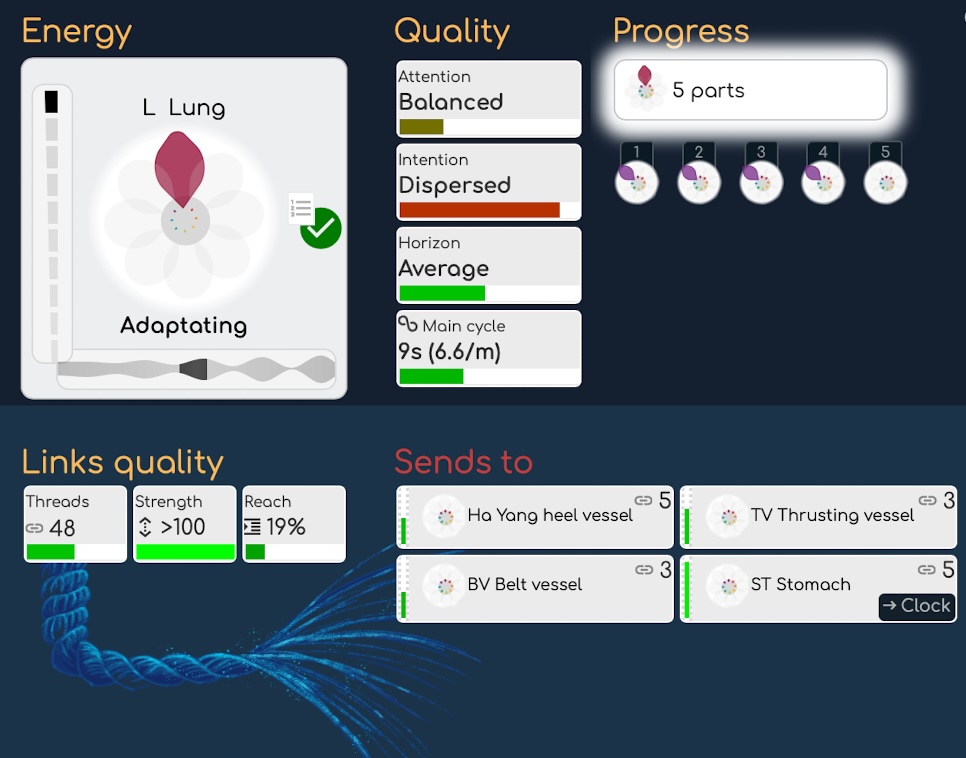 この一次データを得た後、私たちは新しい特性を得て、これらの新しい特性についていくつかの二次分析を行うことができます。例えば、一次分析としてスペクトルを計算しました:FFT(高速フーリエ変換)と呼ばれる数学的アルゴリズムのおかげで、生の記録を波ではなく周波数として表示できます。さて、二次分析では、信号の周波数ではなく、ハーモニクスを抽出することを可能にするケプストラム(2ndオーダーのFFT)を計算します:つまり、調和的に共鳴する周波数を抽出します。これらの結果を使用して、新しいバイオマーカーを得ることができます。
この一次データを得た後、私たちは新しい特性を得て、これらの新しい特性についていくつかの二次分析を行うことができます。例えば、一次分析としてスペクトルを計算しました:FFT(高速フーリエ変換)と呼ばれる数学的アルゴリズムのおかげで、生の記録を波ではなく周波数として表示できます。さて、二次分析では、信号の周波数ではなく、ハーモニクスを抽出することを可能にするケプストラム(2ndオーダーのFFT)を計算します:つまり、調和的に共鳴する周波数を抽出します。これらの結果を使用して、新しいバイオマーカーを得ることができます。
- 別の2ndオーダー分析の例は、各バイオマーカーのエントロピー(または「動揺」)の計算です。つまり、特定のバイオマーカーが静的であるか動揺しているかを示します。
- 2ndオーダー分析の別の例は、バイオマーカーの右側に示される特性、例えば注意、意図、地平線(音楽的特性から抽出された特性)、および主要なサイクルです。
信号に対して多くの2ndオーダー分析が行われており、多くの新しいバイオマーカー情報を得ています。しかし、ここで止まるわけにはいきません。この新しいレベルは、以前には存在しなかったいくつかの新しい興味深い特性を明らかにします。
再度、私たちは非常に多様な研究者によって発表された多くの研究を使用しました。今やECGデータではなく、アーユルヴェーダ、TCM、エネルギー評価、現代医学などの療法特有のデータに基づいています。
三次分析:リンクと共鳴
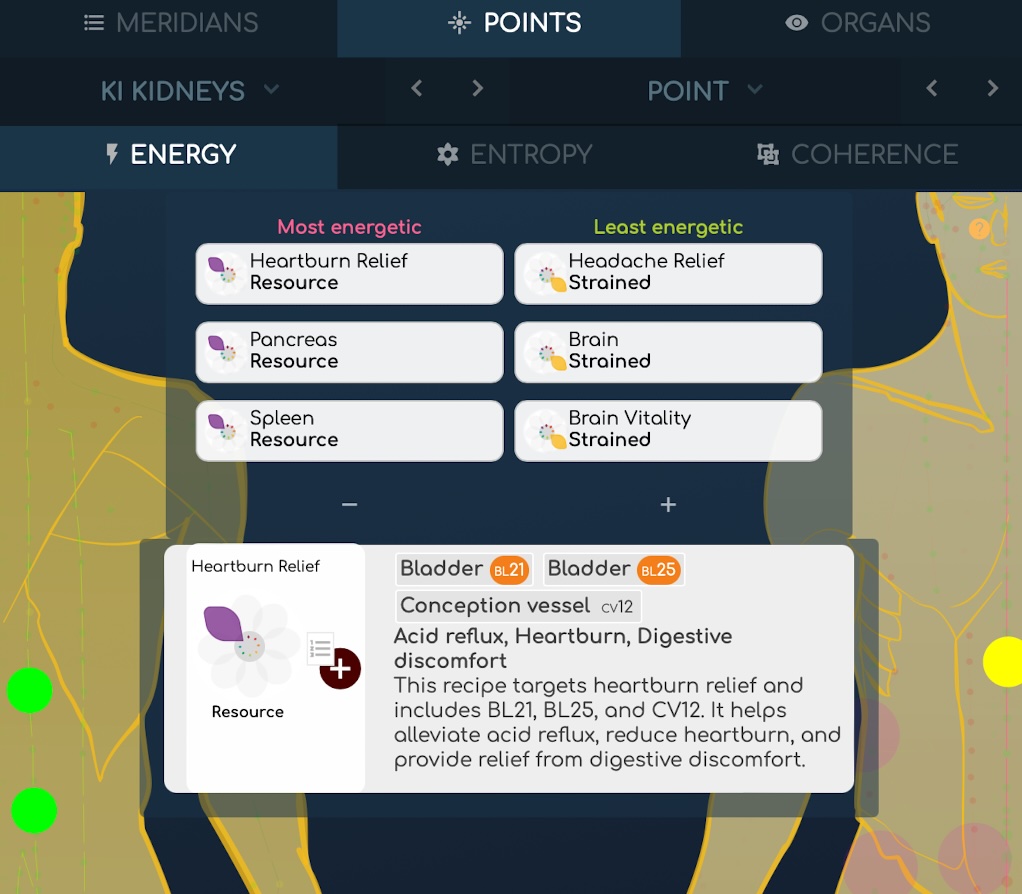 ここに新たな驚異を伴う別の複雑さのレベルが登場します。私たちが持っているすべての2ndオーダーの新しいデータを使用して、新しい特性を計算できます。例えば、要素間のリンクです。これらのリンクはアプリの至る所に表示されており、グラフや身体マップなどがあります。これにより、臓器などの主なエネルギー関係を理解することができます:ある臓器が別の臓器にリンクしている場合、エネルギーの転送が行われていることを示す可能性があり、一方が他方を助けたり、助けられたりしていることを示します。
ここに新たな驚異を伴う別の複雑さのレベルが登場します。私たちが持っているすべての2ndオーダーの新しいデータを使用して、新しい特性を計算できます。例えば、要素間のリンクです。これらのリンクはアプリの至る所に表示されており、グラフや身体マップなどがあります。これにより、臓器などの主なエネルギー関係を理解することができます:ある臓器が別の臓器にリンクしている場合、エネルギーの転送が行われていることを示す可能性があり、一方が他方を助けたり、助けられたりしていることを示します。
これらのリンクは、要素間の共通の共鳴を抽出するために高度なベクトル数学を使用するかなり複雑な多次元アルゴリズムで計算されています。しかし、この複雑さを隠し、要素間の明確なリンクのみを表示するようにしました。
- プロセスの一環として、膨大なデータを計算し、それは各バイオマーカーの「リンクの質」とリンクされた要素として表れます。
- 別の三次の例は、TCMレシピの計算です。特定の症状を治療するためにいくつかの鍼灸ポイントを使用するTCMレシピの論理を逆エンジニアリングしました。それを逆にすることで、これらのポイントがこれらの三次の特性によってリンクされている場合、それは彼らのグループに関連する症状を示す可能性があります。
再び、私たちは治療特有のデータに関する公開された研究を使用しました。TCMレシピを除いて、リンクの論理は、根本原因を見つけるために因果関係を追求しようとする多くの実践者の研究から得られています。
さらに進んでみませんか?
 さて、これを機に、新たに現れた特性について続け、4次レベルの分析を行いましょう。これらの新しいデータポイントを用いて、リソースと優先順位を計算することができます。リソースは、下位の全てのレベルの情報を使用して単一の「リソース値」を計算する4次アルゴリズムによって算出されます。これは、リソースを変更する必要がある場合にリソースページで示されます。それは、特定のファミリー内のバイオマーカーが「寛大さのチェーンの頂点にある」ことを示しています。リソース理論はクリスティーヌ・デゴイの研究に由来し、彼女の今後の著書でより詳しく説明される予定です。
さて、これを機に、新たに現れた特性について続け、4次レベルの分析を行いましょう。これらの新しいデータポイントを用いて、リソースと優先順位を計算することができます。リソースは、下位の全てのレベルの情報を使用して単一の「リソース値」を計算する4次アルゴリズムによって算出されます。これは、リソースを変更する必要がある場合にリソースページで示されます。それは、特定のファミリー内のバイオマーカーが「寛大さのチェーンの頂点にある」ことを示しています。リソース理論はクリスティーヌ・デゴイの研究に由来し、彼女の今後の著書でより詳しく説明される予定です。
一方、優先順位はある意味でアンダードッグ、つまり「食物連鎖の底辺」に位置する部分です。これらは、特定のバイオマーカーのファミリーにおけるエネルギー、動揺、またはコヒーレンスに基づいて、3次の情報およびそれ以下から抽出されます。私たちがエネルギー、動揺、そしてコヒーレンスを計算したことにより、エネルギーが低すぎる、エネルギーが高すぎる、静的すぎる、動揺しすぎる要素、そして何かが進行中であることを示すかもしれないコヒーレントなシステムを優先順位として置くことができます。
さあ、逆に踊りましょう
私たちのH2O水の例に戻りましょう。水を初めて見たとき、あなたはその気体成分から分析することはありません。あなたはただ、飲むことができること、泳ぐことができること、他の元素と混ざることができることなど、上位の性質を見ています。通常、複雑なシステムを見るとき、私たちは外側からそれを見て、上位の性質しか見えません。そして、追加の秩序のレベルを明らかにするたびに、私たちはそれが日常のユーザーにとってどれほど便利であるかを認識しました。したがって、BioCoherenceでは、情報の重要性を逆転させ、リソース(4次の情報)、優先順位(3次の情報)、バイオマーカーの花(2次の情報)、およびバイオマーカーの特性(3次の情報)から始める傾向があります。最初のレベルの順序情報(波とスペクトル)に下ることはまだ可能ですが、日常的に最も価値があるのは上位のレベルです。
 複雑性の順序は、ホーム画面の右上の矢印を通じて示されています(それぞれのレベルで数学をやり直すためにクリックできます)が、メニューの論理(およびレポートの順序)は逆転しています:上位のレベル(バランス:リソース、優先順位、レポート)から始まります。これは通常、最初に見るべき最も重要な情報です。
複雑性の順序は、ホーム画面の右上の矢印を通じて示されています(それぞれのレベルで数学をやり直すためにクリックできます)が、メニューの論理(およびレポートの順序)は逆転しています:上位のレベル(バランス:リソース、優先順位、レポート)から始まります。これは通常、最初に見るべき最も重要な情報です。
これでスキャン部分は終了です。